LinkedList源码解析(一)
前几篇文章分析过 List 接口的一个重要实现 ArrayList,本篇博客开始介绍另一个重要实现 LinkedList。
一、与 ArrayList 的区别
ArrayList 使用数组存储数据,且数组元素数大于实际存储的数据以便增加和插入元素,允许直接按序号索引元素,但是插入元素要涉及数组元素移动等内存操作,所以索引数据快而插入数据慢。而LinkedList使用双向链表实现存储,按序号索引数据需要进行前向或后向遍历,索引就变慢了,但是插入数据时只需要记录本项的前后项即可,所以插入速度较快。
二、LinkedList 继承关系
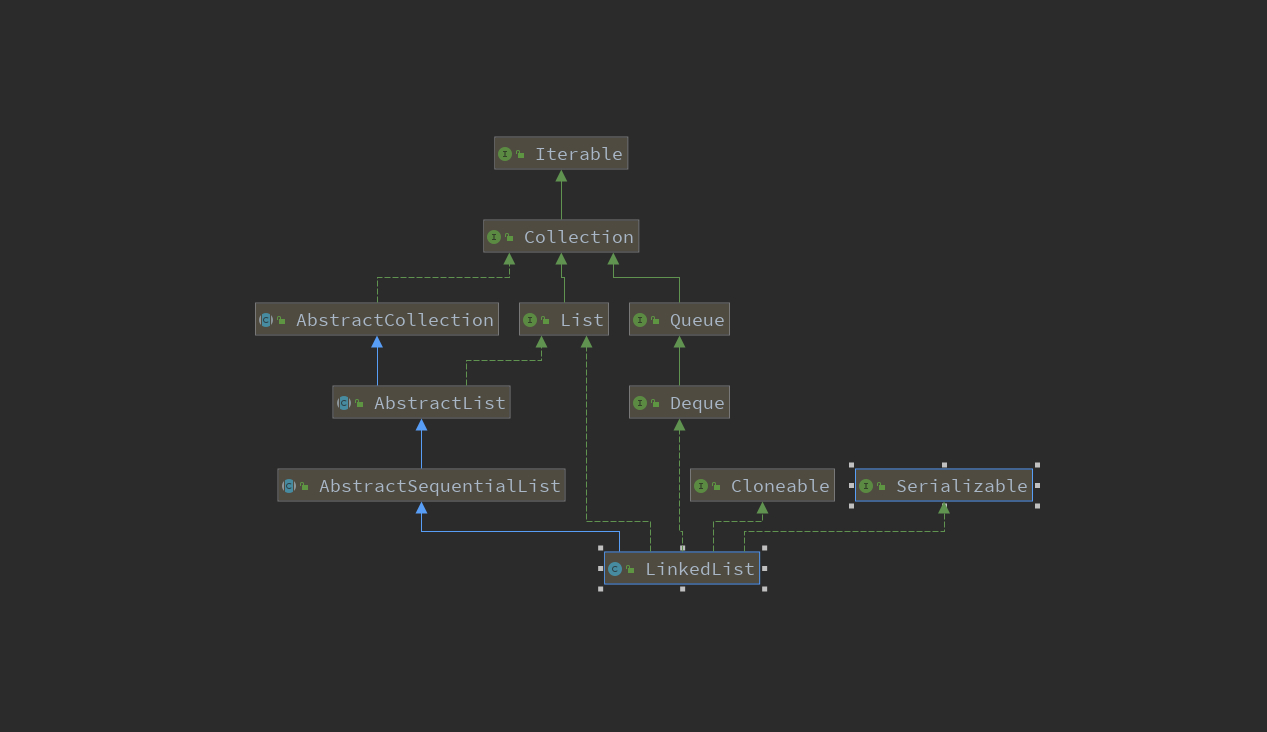
不同于 ArrayList ,LinkedList 实现了 Deque 接口,使得 LinkedList 可以被当作堆栈和队列来使用。
三、源码解析
1、内部类Node
LinkedList 中的每一个元素就相当于一个 Node 类,LinkedList 集合就是由多个 Node 类拼接而成。1
2
3
4
5
6
7
8
9
10
11
12
13
14private static class Node<E> {
// 当前节点的值
E item;
// 指向下一个节点的引用
Node<E> next;
// 指向上一个节点的引用
Node<E> prev;
// 构造函数
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
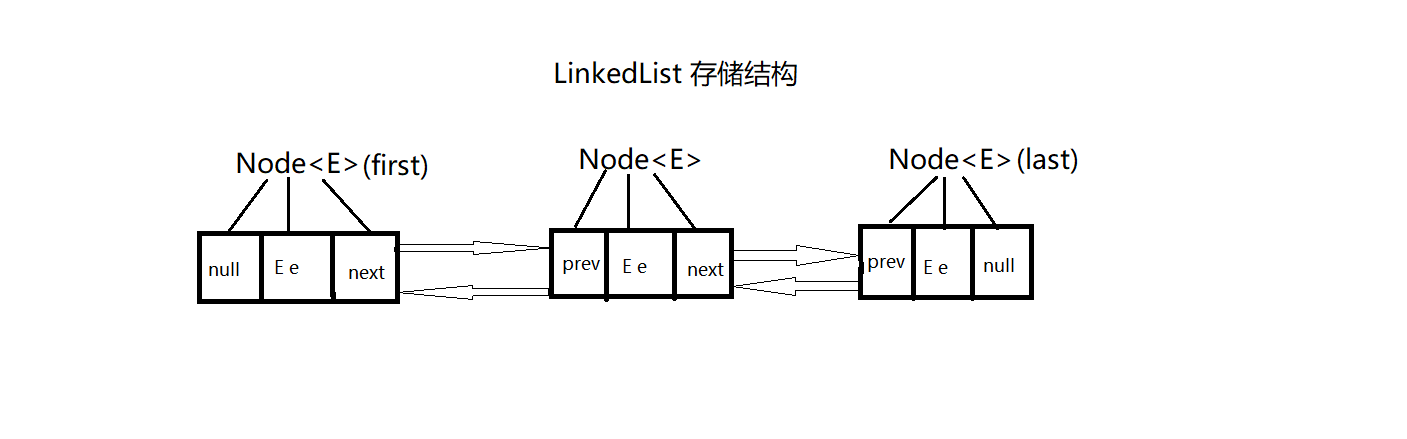 此时,集合中有三个元素,为三个 Node 对象
此时,集合中有三个元素,为三个 Node 对象
2、add(E e)
1 | // 将指定的元素添加到末位 |
linkLast(e) 方法:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21/**
* Links e as last element.
*/
void linkLast(E e) {
// 先保存最后一个节点
final Node<E> l = last;
// 实例化新的Node对象,prev 指向当前最后节点,item 值为添加的元素, next 为 null
final Node<E> newNode = new Node<>(l, e, null);
// 新的节点即为最后的节点
last = newNode;
/*
* 如果最后一个节点为null,则集合为空,newNode 节点即为 first 节点
* 不为null,将 newNode 节点链接到尾部
*/
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
LinkedList 没有扩容机制,所以 add() 方法较之 ArrayList 的 add() 方法,速度较快。
3、add(int index, E element)
1 | // 将元素插入集合中的指定位置 |
看看 node(index) 方法,返回 index 位置的 Node 对象:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22/*
* node 方法采用二分法查找index位置对应的Node对象
* 最坏的结果为index在左半区的最后一位或者右半区的第一位
*/
Node<E> node(int index) {
// assert isElementIndex(index);
// size >> 1 相当于 size = size / 2, 结果会向下取整
if (index < (size >> 1)) {
// 如果index在左半区,则从first节点开始正序查找
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
// 如果index在右半区,则从last节点开始反序查找
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
得到 Node 对象,然后 linkBefore(element, node(index)) 方法将元素添加到相应的位置:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16void linkBefore(E e, Node<E> succ) {
// assert succ != null;
// index - 1 位置的节点
final Node<E> pred = succ.prev;
// 实例化新的Node对象,prev为 index-1位置的节点, item为元素e,next保存的引用为当前succ节点
final Node<E> newNode = new Node<>(pred, e, succ);
// 设succ上一个节点的引用为newNode,现在succ节点在 index+1 位置
succ.prev = newNode;
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
}
linkBefore() 方法执行过程为:
4、addAll(int index, Collection<? extends E> c)
1 | // 将指定集合中的所有元素按照指定开始位置插入到集合中 |
5、addFirst(E e)
1 | // 在集合头部添加新元素 |
其基本原理如图: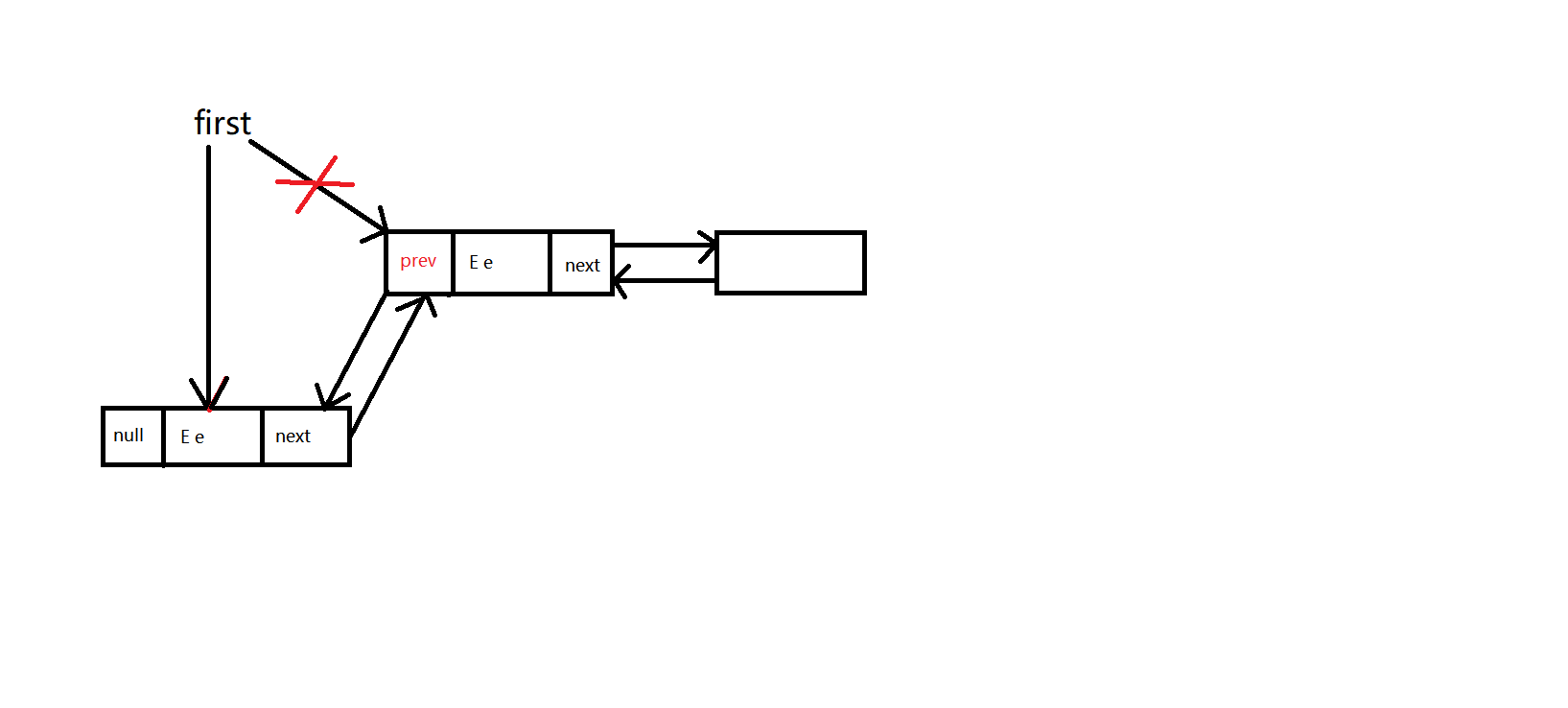
addLast(E e) 原理与 addFirst(E e) 相同,差别在于添加位置不同。
6、remove(int index)
1 | // 删除指定位置的元素 |
node(index) 方法在 add(int index, E element) 时已解析过。看看 unlink()方法:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35/**
* 移除指定节点数据
*/
E unlink(Node<E> x) {
// assert x != null;
// 节点值
final E element = x.item;
// 下一个节点
final Node<E> next = x.next;
// 上一个节点
final Node<E> prev = x.prev;
/*
* 将指定节点的前后节点联通
* 从而达到移除指定节点的效果
*/
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}
6、removeIf(Predicate<? super E> filter)
removeIf() 方法继承自 Collection:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21/*
* 按照一定的规则过滤集合中的元素
*/
default boolean removeIf(Predicate<? super E> filter) {
// 判断参数是否为空
Objects.requireNonNull(filter);
// 集合是否做出改变
boolean removed = false;
final Iterator<E> each = iterator();
while (each.hasNext()) {
/*
* 如果集合元素满足指定的规则
* 调用迭代器Iterator 的remove 方法移除元素
*/
if (filter.test(each.next())) {
each.remove();
removed = true;
}
}
return removed;
}
示例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19public class Test {
public static void main(String[] args) {
LinkedList<Integer> list = new LinkedList<>();
for (int i = 0; i < 10; i++) {
list.add(i);
}
System.out.println(list);
// 输出: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
list.removeIf(it -> it > 5);
System.out.println(list);
// 输出: [0, 1, 2, 3, 4, 5]
}
}